지난 번에는 웹 스크래핑을 위한 파이썬 개발환경을 구성하는 방법을 알아봤습니다. 이제는 준비된 환경에선 웹(인터넷)에 있는 데이터를 어떻게 가지고 오는지 알아보겠습니다.
소스(출처)를 알아내라!
우선 데이터를 제공하는 소스를 정확히 찾아내야 합니다. 이때는 브라우저의 개발자 도구를 활용하게 됩니다. 익스플로러 브라우저의 경우 F12 단축키로 개발자도구를 열 수 있습니다.
- 우선 데이터를 제공하는 곳을 찾습니다.(예제에서는 금융감독원 전자공시 dart.fss.or.kr)

-
개발자 도구의 네트워크 탭에서 레코딩을 시작합니다.

-
브라우저에서 조회를 합니다. 개발자 도구를 다시 열어보면 조회를 통해 발생한 HTTP REQUEST가 표시됩니다.
-
요청은 보통 CSS, JAVASCRIPT, 이미지, HTML 등으로 구분할 수 있습니다. 어떤 요청에 원하는 데이터가 나오는지 확인해 봅니다. 요청을 선택하면 상세 내용이 표시되고 본문 탭의 응답 본문을 확인해 봅니다.

-
일단 어느 주소에서 원하는 데이터를 가져올 수 있는지 찾아냈습니다. HTTP REQUEST 방식에 따라 요청 본문(POST) 또는 매개 변수(GET)를 확인하면 어떤 변수들이 필요할지 확인할 수 있습니다.
HTML 분석하기
응답으로 받은 데이터 중 필요한 데이터를 추출하기 위한 처리를 만듭니다.
- 구조를 분석하기 위해 개발자 도구의 DOM 탐색기를 사용합니다.

-
지금의 경우 listContents 라는 id의 div안에 table 의 데이터를 추출하면 될 것 같습니다.
- 자바스크립트로 인해 DOM에서 보이는 내용과 실제 요청의 결과는 조금 다를 수 있습니다.
requests로 요청하고 Beautiful Soup 으로 응답 해석하기
이제 입력(요청 주소, 파라미터)과 출력(응답과 구조)이 대략 정해졌습니다. HTTP 요청에는 requests 라이브러리가, 응답 데이터 해석과 추출에는 BeautifulSoup 라이브러리를 사용할 수 있습니다.
- 사용할 라이브러리를 가져옵니다.
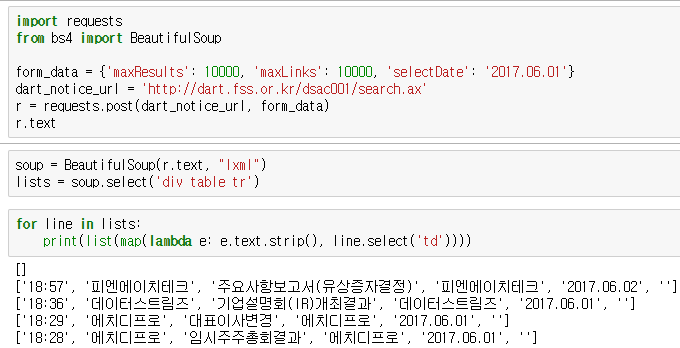
import requests
from bs4 import BeautifulSoup - 요청 데이터를 설정합니다.
form_data = {‘maxResults’: 10000, ‘maxLinks’: 10000, ‘selectDate’: ‘2017.06.01’}
dart_notice_url = ‘http://dart.fss.or.kr/dsac001/search.ax’ - 요청하고 응답 데이터를 해석합니다.
r = requests.post(dart_notice_url, form_data)
soup = BeautifulSoup(r.text, “lxml”)
lists = soup.select(‘div table tr’) - 응답 데이터 중 필요한 부분만 추출합니다.
list(map(lambda e: e.text.strip(), lists[1].select(‘td’)))
- 실행하면 아래의 결과가 표시됩니다.
selenium 사용하기
최근의 웹 환경에서는 자바스크립트가 광범위하게 사용되고 있습니다. requests 라이브러리는 요청과 응답만을 처리하기 때문에 자바스크립트의 실행이 필요한 경우 스크래핑이 어려울 수 있습니다. selenium은 브라우저 자동화 도구로 여러가지 브라우저를 통제할 수 있고 자바스크립트의 실행이 가능하기 때문에 실제 사용자가 하듯이 브라우저를 컨트롤하고 스크래핑할 수 있습니다.
- 일단 selenium을 설치합니다.
pip install selenium - 링크 에서 브라우저 버전에 맞는 드라이버를 적당한 곳에 위치시킵니다.
- 아래는 그룹웨어에 로그인하고 화면을 캡쳐해 저장하는 샘플 코드 입니다.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# get the path of IEDriverServer
driver = webdriver.Edge("D:\\Apps\\selenium-driver\\MicrosoftWebDriver.exe")
driver.get("iworld.ibksystem.co.kr")
elem_id = driver.find_element_by_id('id')
elem_id.clear()
elem_id.send_keys('id') # ID 입력
elem_pw = driver.find_element_by_id('password')
elem_pw.clear()
elem_pw.send_keys('password') # 패스워드 입력
# elem_btn = driver.find_element_by_xpath("//div[@class='btn_login']//button")
elem_btn = driver.find_element_by_css_selector("div.btn_login button")
elem_btn.click()
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "ptlMemo-blueimp-gallery"))
)
# driver.implicitly_wait(5)
driver.get_screenshot_as_file('groupware-login.png')
driver.close()
- 코드를 실행하면 브라우저가 열리고 로그인 하는 모습이 보입니다.
- 캡쳐가 잘 되었습니다!

정리
- 이번에는 웹 스크래핑의 전체 과정을 좀 더 자세히 살펴보았습니다.
- 웹 스크래핑에 있어서 파이썬이 갖는 매력은 풍부한 라이브러리와 각종 사례, 커뮤니티에 있습니다. 잘 되지 않으면 커뮤니티에 질문을 올려보세요.
- 다음번에는 데이터를 저장하는 방법을 알아보겠습니다.
Tips
- selenium은 웹 애플리케이션의 테스트 자동화를 위해 사용할 수 있습니다. 인터넷 익스플로러 이외에 Firefox, Chrome 등 다양한 브라우저를 사용할 수 있으며 PhantomJS과 같은 UI 없는 브라우저를 사용해 빠른 테스트를 할 수 있습니다.